- Patent

- Trademark
- Innovation
- Solutions
- Contact












- Learn & Support
- Learn and support
- Webinars & EventsAre you interested in attending one of our online or onsite event?
- Product TrainingsCustomer success is our priority. Increase your skills in the use of Questel’s software
- Product NewsA platform dedicated to software and platforms news and evolutions
- Best-in-class Customer ExperienceOur goal is to exceed our clients' expectations and share best practices
- IP TrainingIncrease the IP-IQ of your entire organization with engaging IP training programs
- Newsletter subscriptionSign up for our quarterly patent and trademark newsletters and set your email preferences below.
- Webinars & Events
- Resource HubStay up-to-date with industry best practices with our latest blogs
- Resource Hub
- About Questel
- Learn & Support
- Learn and support
- Webinars & EventsAre you interested in attending one of our online or onsite event?
- Product TrainingsCustomer success is our priority. Increase your skills in the use of Questel’s software
- Product NewsA platform dedicated to software and platforms news and evolutions
- Best-in-class Customer ExperienceOur goal is to exceed our clients' expectations and share best practices
- IP TrainingIncrease the IP-IQ of your entire organization with engaging IP training programs
- Newsletter subscriptionSign up for our quarterly patent and trademark newsletters and set your email preferences below.
- Webinars & Events
- Resource HubStay up-to-date with industry best practices with our latest blogs
- Resource Hub
- About Questel

Patent sequence search - Orbit BioSequence
OBS: From simple patent sequence search to variant analysis
DNA, RNA sequences as well as proteins have been disclosed in patents since the 60s and a few even before that. Many laws have been created and modified over time to allow different types of biological material to be patented, such as naturally occurring sequences, modified sequences, sequences used in diagnostics, sequences from plants and many other types. We have recently seen that vaccines are a hot topic and some, such as RNA vaccines, do include sequences. Industrial domains that publish sequences could seem surprising, but the food industry or detergent manufacturers for instance are some of them. Obviously, pharmaceutical industry, biotech, agrochemical and seed companies produce the bulk of sequence patents. So, why is patent sequence searching important and why is it different to other types of patent searching?
Patent Sequence Data
Starting in the 90s, and the human genome project, genomic and mRNA sequences started to become more common in patents. In some cases, whole genomes (from bacteria, fungus) which can be made up of millions of base pairs were published. Private companies disclosed and, in some cases claimed millions of short sequences. All this is happening when all patents were purely filed on paper. Electronic filing of patents and supplemental materials such as sequence listings finally became available in part due to sequence patent . Since then, we have seen an increase in the number of patents with sequences, and despite the massive rise in Chinese patents, the worldwide newly published number of patents with sequences still follows a linear curve.
 Historical trend of newly published sequence patents from 2000 to 2020 available in Orbit BioSequence.
Historical trend of newly published sequence patents from 2000 to 2020 available in Orbit BioSequence.
The historical big three authorities (USPTO, EPO and WIPO) publish their sequences. Some other authorities are very compliant such as JPO, KIPO and CIPO. Others are less systematic or stuck in the past, unfortunately. But even for highly compliant authorities, rules and laws on what sequences should be disclosed vary. It is, thus, highly recommended to have a family view of your patents since a sequence patent might be different in an EPO document than in the USPTO or WIPO documents of the same family.
Why patent sequence search is different?
Traditional IP searching is done with keywords. Since searching with keywords is imperfect, they are often combined with patent classes, synonymous lists, and many other features that, basically, attempt to alleviate the pain induced by the lack of accuracy of keywords.
Biological sequence searches are different for several reasons. First, there is a common language to describe DNA/RNA and amino acid sequences, entirely independent from the native language the patent is written in. So, no need for natural language translation.
Second, since sequences can be very long, several publication standards have existed over time to treat them separately in a sequence listing. Thus, a large majority of published sequences are simple to treat electronically. This can be contrasted with chemistry where images are still an acceptable form of publication.
Third, unless your sequence is very short, you will always want to find sequences similar to yours, not just identical. This is particularly important since small errors (OCR mistakes, publisher errors) can be somehow controlled. By contrast, if you searched for the keywords “bread yeast”, you would not find “bead yeast” even if the latter could be a spelling mistake.
Fourth, for the last 20 years or so, sequences published in a patent are numbered and referred to by the keywords SEQ ID NO. It is easy in most cases to know if, say, hit sequence 5 is claimed since it is referred to by its number in the claims section as SEQ ID NO. 5. This is a unique feature of sequences and one that is critically important, allowing us to highlight sequence instances as (claimed) for instance.
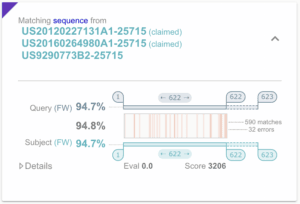
A sequence aligned to a sequence appearing in three USPTO documents, claimed or not in Orbit BioSequence.
A variant analysis will stack all patent sequences aligned to your query and will give you a global view for each query position. In other words, it will create a multiple alignment based on your query sequence. You can query, modify, and export the dataset, and most importantly, explore the variations to give you new insight into what your competitors are doing or what area are never modified for instance.

Variations at several positions using Orbit BioSequence Variant Analysis
Orbit BioSequence (OBS)
With an extensive access to patent sequences as well as non-patent sequences, Orbit BioSequence is the perfect tool for your FTO, patentability and business intelligence searches. By easily combining patent data and sequences, OBS will make your patent sequence searches a lot easier than other tools purely dedicated to sequences. Antibody and CDR, genes, primers can all be used, combined, and explored.
Interested to find out more? Contact us for specific advice or support, or watch the recording of our recent webinar Smart & visual sequence variations explorer in patent data By Orbit BioSequence.